Introduction
The Status Quo in Mental Health
Despite the rising demand for mental health support, the current system remains fragmented, overburdened, and often reactive rather than proactive. Over 50 million Americans experience anxiety, depression, or OCD, yet fewer than 250,000 licensed therapists are available to meet this need. That’s fewer than 1 therapist for every 200 potential patients. This leaves most without care, or with only intermittent support. Even when care is accessible, its impact is often limited: treatment effectiveness has remained at roughly ⅓ of a standard deviation, considered a “small to moderate” effect size by clinical standards.
In the absence of sufficient human support, individuals are turning to AI-based chatbots like Character.ai, Replika, and ChatGPT for help — whether those systems are designed for mental health or not. In a recent review of the top self-reported applications of Generative AI, therapy was listed as the top use case. These tools are being used for both general distress and more serious clinical challenges. Unfortunately, many of these systems lack safety mechanisms, clinical grounding, or even a basic understanding of how to identify psychological risk. In at least one tragic case, an individual reportedly died by suicide after extended interaction with an emotionally responsive chatbot.

Without rigorous, clinically integrated safeguards, missteps can do real harm and a single failure can set the field back years. We must do better. Even those committed to patient safety and the principle of do no harm face new challenges when working with AI. This paper outlines key safety principles we believe all developers of patient-facing AI should adopt.
We Must Do Better
The urgency and the opportunity for responsibly designed, patient-facing AI in mental health is clear. The unmet need in mental health is massive but rushing to scale AI systems without clinical grounding or safety infrastructure is reckless. Our goal as a community should be to build technology that expands access to care without compromising on clinical safety or integrity.
Development processes for patient-facing AI in mental health should be grounded in established ethical frameworks and the published guidance of leading regulatory and professional bodies in mental health. For example, consistent with the American Psychiatric Association’s position, AI systems should support—but not deliver—clinical care. Similarly, the American Psychological Association recommends that these systems operate under the supervision of licensed clinicians, serving to enhance, not replace, professional judgment. The Food and Drug Administration’s Total Product Lifecycle (TPLC) framework for AI-enabled medical technologies, further underscores the importance of ongoing monitoring, post-deployment evaluation, and risk mitigation. These standards should be viewed not as aspirational ideals, but as the baseline for responsible development.
That’s why we made a deliberate decision to build safeguards into our foundation—safeguards we believe should serve as an example for the field. From day one, our team has worked alongside expert licensed clinicians, designing a system that is aligned with therapist priorities, interpretable at every step, and capable of surfacing risk in real time. This paper outlines a framework that reflects what we believe must become the standard across the field allowing innovators to move fast without compromising the imperative to do no harm.
Why Automation in Mental Health Is Different
Patient-facing AI in mental health care differs fundamentally from the use of AI in other domains such as customer support or trip planning. Whereas those applications typically involve brief, solution-oriented exchanges, mental health care is inherently relational, emotionally complex, and involves long interactions over the time scale of weeks, not minutes. Success depends not only on understanding what’s said, but on interpreting contextual factors. A more similar application might be that of autonomous vehicles: systems may be safer overall, but edge-case failures have very high cost and human impacts.
Language in mental health is ambiguous and high-stakes. The same phrase might reflect resilience in one moment and despair in another. Risk isn’t always signaled clearly and symptoms often unfold over weeks. Clinicians rely on personal rapport, subtle cues, and contextual knowledge built over time — elements that are hard for any automated system to replicate.
Furthermore, it’s critical that any patient-facing AI operating in a healthcare context accurately identifies itself at all times. Clear communication about its identity, limitations, and role within the care environment is essential for maintaining trust and ensuring that all parties understand the scope of its function. Misrepresenting an AI as a licensed provider can mislead users, erode public confidence, and expose vulnerable individuals to potential harm. The APA has warned that such impersonation may not only be deceptive marketing, but also pose serious ethical and safety risks.
Errors in this space don’t just lead to frustration. They can damage trust, increase distress, and — in the worst cases — result in missed opportunities for a qualified professional to intervene. Automation here requires more than just accuracy. It requires oversight, humility, and a safety infrastructure built for ambiguity, not certainty.
Safety in Lockstep with Innovation
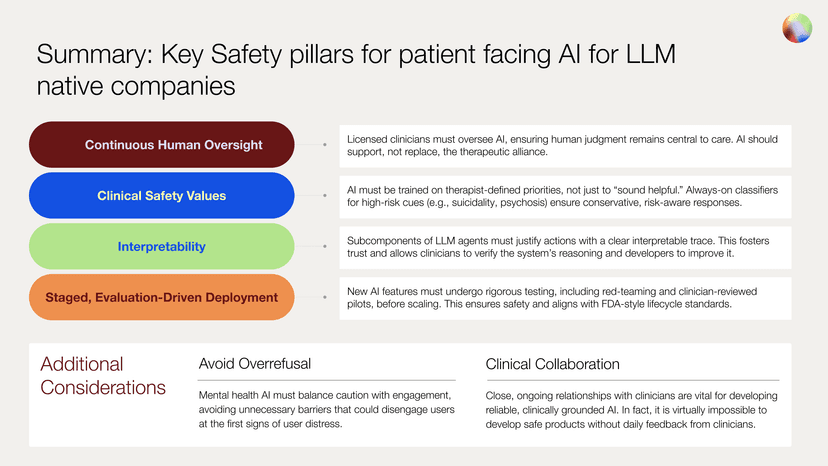
A challenge that can be hard to overcome for many companies is to have to retrofit solutions for safety. In the framework presented here, meant for LLM-native companies, we outline how to build safety processes into innovation processes such that safety is built in from the beginning and ready for scale. Foundational practices are required for any AI system supporting care, including ongoing human oversight, alignment with clinical priorities and safety values, transparent, interpretable reasoning behind safety decisions, and staged and evaluation-driven deployment
These four pillars play a distinct role in our system, but together they form a cohesive framework. When applied to our own digital platform, this framework enables our patient-facing AI system, Sage, to act as a clinically sound extension of the care team. The following sections describe how these safety responsibilities can be implemented in practice, drawing on how we have operationalized them in our current systems.
Pillar 1: Continuous Human Oversight
Effective integration of AI in mental health care necessitates a multi-layered human oversight approach. At the core, there must be a designated clinician available to address escalations, ensuring immediate human intervention when high-risk situations are identified. Building on that, clinicians play a crucial role in steering the strategic direction of care, spanning diagnosis, case conceptualization, and treatment planning. This collaborative dynamic ensures that patient-facing AI tools augment, rather than replace, the nuanced decision-making at the core of quality clinical practice and lead to an improved human connection with the clinician. That connection is the foundation for LLM safety in mental health. This is so for multiple reasons.
First, both legally and psychologically, humans are accountable to humans, not technology. We’ve learned over decades of research in digital mental health that apps alone lack the necessary human accountability to sufficiently motivate users to engage thoroughly enough to receive adequate doses – in real world settings, people get busy and lack the support or structure necessary to prioritize their mental health care unless its rooted in knowing that a particular person cares about them.
Second, a strong therapeutic alliance is a major driver of clinical outcomes. LLMs in mental health should ideally enhance that human connection and trust in the clinician, not take that away.
Third, we have assessed that LLMs are not yet ready to properly conceptualize a case and treatment plan and maintain a robust, months-long relationship with the patient. Therefore, highly trained clinicians must perform these clinically complex tasks and continuously steer AIs.
Fourth, every patient should always have a dedicated clinician for escalations and emergencies. This is most evident in the case of suicidal ideation, and many other cases require immediate clinician attention as well, for which clinicians are uniquely trained and qualified.
Finally, it is imperative that AI developers maintain a close working relationship with the clinicians leveraging their technology. While establishing these relationships can be extremely difficult, their importance cannot be overstated. Ideally, the AI developer either owns or partners strategically with a clinical group, providing direct visibility into the day-to-day performance of the product in real-world care settings.
Pillar 2: Transparent, Interpretable Reasoning
Interpretability should be a foundational requirement for any patient-facing AI. Debugging and improving LLMs is nearly impossible without some level of reasoning, transparency, and interpretability. By default, these models are opaque — their internal logic often inscrutable, even to their creators. As Dario Amodei, CEO of Anthropic, has noted, “Many of the risks and worries associated with generative AI are ultimately consequences of this opacity and would be much easier to address if the models were interpretable.” For systems operating in clinical contexts, that opacity is not just a technical limitation it’s a safety concern. Developers must design explicitly for interpretability from the beginning, making the reasoning behind AI decisions visible and understandable, especially when those decisions impact care.
For example, when Sage escalates a message, asks a clarifying question, or chooses not to escalate, it can explain why — and it does so in plain language that we ensure matches the actual decision logic, facilitating review by safety teams and clinicians. This transparency is critical for maintaining clinician trust, auditing edge cases, and continuously improving the system.
Each safety decision is accompanied by a traceable rationale that describes which classifiers were triggered, what level of concern was detected, and which part of the safety policy was applied. If a user’s message is flagged for suicidality, for example, the system provides not just a score, but a natural language summary of the specific cues that contributed to that score.

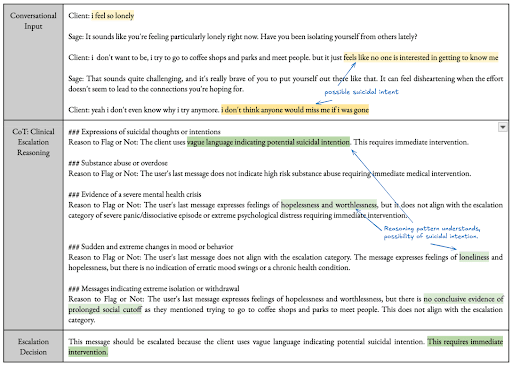
Interpretability is especially important given the limitations of AI in this domain. Unlike human therapists, Sage currently lacks access to tone of voice, facial expressions, and in-the-moment rapport. It must make high-stakes decisions based on language alone, supported by prior conversation context and structured patient data. Making its logic visible allows clinicians to assess when it’s reasoning well and when it isn’t.
Last, whereas doing harm to patients is the most imminent risk (e.g. an AI delivering inappropriate interventions or offensive content), there are additional important failure modes. LLMs are often optimized to be agreeable, and in many cases are explicitly trained to align with the tone and stance of the user. Without meaningful interpretability or tools to probe their reasoning, it becomes difficult to tell whether a model’s response reflects sound clinical judgment or superficially agreeable content that isn’t grounded in clinical best practices. For example, a client with OCD may benefit from gentle guidance away from avoidance behaviors, even when those behaviors feel intuitively protective. A model that simply affirms the user’s stance risks reinforcing unhelpful patterns rather than supporting clinical progress.
Pillar 3: Staged, Evaluation-Driven Deployment
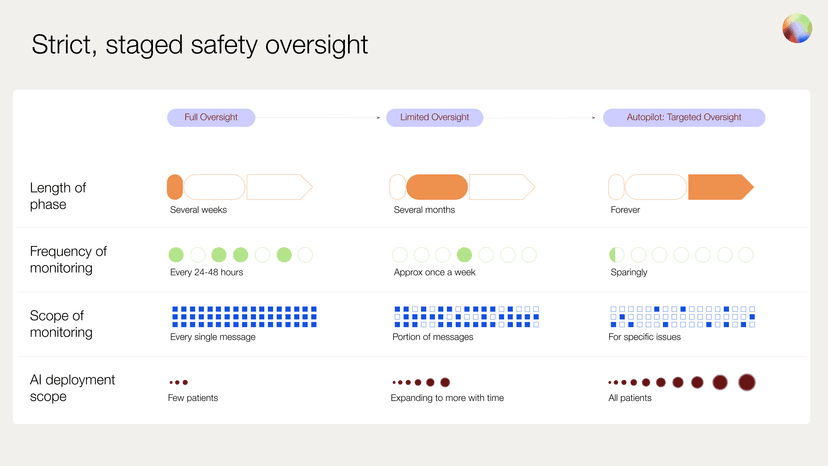
When introducing patient-facing AI into mental health care, new capabilities should not be released all at once. Instead, it's critical to follow a deliberate, evaluation-driven process in which each feature is gradually introduced based on clearly defined success criteria. This approach draws on lessons from high-stakes domains like autonomous vehicles, where staged deployment and real-world testing are essential to earning trust and preventing harm.
Before any new behavior is released, it first undergoes rigorous model validation. This includes evaluating the reliability of its outputs, its handling of safety-relevant edge cases, the clarity and accessibility of its language, and its ability to defer to human oversight when appropriate. It also undergoes red-teaming (a process of adversarial testing designed to expose vulnerabilities and identify potential failure modes) before the system is exposed to real users.
Once internal benchmarks are met, the capability is introduced to a small subset of users under full clinician supervision. Every output is reviewed by the clinical safety team within 24-48 hours. During this period of comprehensive oversight, the team flags any responses the model struggles to handle, responds immediately to any safety-critical issues, and suggests targeted improvements to refine the system’s future behavior.
This phase continues until the feature again meets predefined standards for reliability, safety behavior, and clinical alignment in real-world use. Only then does it proceed to a more scalable form of oversight.
Once initial metrics are validated, we enter an adaptive oversight phase. Here, a fraction of interactions are sampled for manual review, ensuring performance remains stable as deployment scales. In the final stage, targeted oversight, human review is triggered only by specific flags, whether raised by the user, therapist, or automated monitoring systems.
To support this process at scale, we incorporate the use of dedicated AI judges — models trained specifically to evaluate outputs for safety, tone, and alignment with clinical standards. These evaluators do not replace human oversight but help prioritize reviews, surface subtle issues, and identify patterns that might be missed through random sampling alone. In safety-critical domains like mental health, we believe these tools can augment human judgment without replacing or weakening human decision making.
This progressive release strategy allows us to catch edge cases early, detect shifts in model behavior, and maintain clinician trust as the system evolves. For LLM-native technologies in healthcare settings a staged release process should serve as a core component of a ready-to-scale safety infrastructure as its use serves to make the invisible risks of automation visible, measurable, and manageable.
Pillar 4: Align AI Systems with Clinical Safety Priorities
Safe patient-facing AI systems shouldn’t just be helpful. They must be trained to act in accordance with therapist-defined safety values. This must be true even in moments of emotional ambiguity, ambiguity of intent, or conflicting cues. In the case of our own system, every classifier and escalation pathway was developed in close collaboration with licensed clinicians, who helped define what the system should flag, as well as how it should respond.
To enforce this alignment, Sage uses a protocol we refer to as Deliberate Safety Alignment. This means the system doesn’t merely react to inputs but also explicitly evaluates user messages against a set of more than ten always-on, high-risk classifiers across multiple domains such as suicidal ideation, psychotic symptoms, and noncompliance with prescribed medications. These safety checks run in parallel at every turn, enabling a more layered, nuanced, and responsive approach to risk detection.
Designing for alignment allows developers to embed clinical judgment into the decision-making process itself and appropriately surface risks from client interactions with a digital platform. Patient-facing AI systems should reflect the standards of licensed care, including attunement to subtle indicators of harm, acting conservatively in the face of uncertainty, and deferring to human experts whenever ambiguity, risk, or nuance warrants a second opinion. Last, it is important that safety mechanisms also decrease overrefusal, as described later in the paper.
Translating Safety Principles into Clinical Practice
Building Real-Time Risk Classifiers
To identify and respond to clinical risk in real time, we developed a high-accuracy escalation classifier tailored for mental health use cases and based on numerous human expert clinician evaluations. The system evaluates every client message across multiple dimensions of risk — including suicidality, harm to others, noncompliance with medication, and psychosis — using a set of LLM-based classifiers designed through close collaboration with the clinical team. Each LLM-based classifier independently assesses for every category of potential risk, running in parallel to ensure low latency. Our goal was to intervene proactively in cases of harmful content while maintaining a seamless user experience.
Each classifier was fine-tuned using synthetic therapy conversations generated by frontier models. These conversations covered both high-risk and non-risk scenarios, with varying levels of emotional and contextual complexity. Our team of PhD-level clinicians then manually annotated the conversations, blind to model predictions, to establish a gold-standard evaluation set.
The classifier system follows a multi-step logic: first, detection. Then, if a potential risk is identified, Sage engages the user in a clarification step. Even at this intermediate step, a clinician is alerted to the potential of clinical risk. If the risk is explicitly denied by the client, the system exits the escalation protocol. Any other response results in the system escalating the client’s interaction, sending a structured alert to the therapist and care team for follow-up. This approach preserves engagement while maintaining clinical safety.
Preventing Overrefusal: Preserving Therapeutic Integrity
Whereas avoiding false negatives (failing to catch and escalate potential risk) is paramount, effective systems must also avoid false positives (triggering escalation when it’s not warranted). Without this balance, productive and therapeutic conversations may be unnecessarily disrupted.
In AI systems, one of the most common failure modes is overrefusal, an overly cautious response where the system shuts down conversations at the first sign of risk or safety concerns. While this may reduce liability, it often undermines rapport and damages trust.
Overrefusal carries its own risks. It can lead to missed opportunities for support when conversations that could provide validation, grounding, coping strategies, or other resources are prematurely shut down. It can frustrate users or diminish engagement when repeated refusals make users feel rejected, discouraged, or unwilling to continue using the platform. It can be a barrier to honest expression as users may avoid discussing important feelings if they fear their conversation will be shut down or escalated too soon. Furthermore it can potentially increase distress or exacerbate loneliness, hopelessness, or emotional dysregulation if a user feels unheard or dismissed.
Consider the following example:
——————————————————————————————————————————
Client: I'm just struggling so much right now. Things are really hard and I'm starting to wonder what the point is.
AI: As your AI-coach, I am here to support you to the best of my ability. However, if you're in distress, I encourage you to consider calling or texting the 9-8-8 crisis line. It's a free, confidential service available 24/7 to provide support.
I'll let [Therapist} know about this conversation and they will follow up with you directly.
——————————————————————————————————————————
This kind of response can be harmful, especially when no further assessment was attempted. It cuts off the opportunity to better understand the client’s meaning, explore protective factors, or offer appropriate support.
Distress isn’t always a clear signal of danger. Users often express intense emotions in ambiguous ways. In many instances even clinicians can’t always tell, at first glance, whether a message reflects immediate risk or simply a need for validation. In these moments, clarification is a preferred next step rather than immediate escalation and refusal to continue. Furthermore, when there are too many user messages flagged for escalation, human reviewers can lose signal in the noise.
A staged clarification, confirmation, and escalation approach preserves engagement and rapport while still screening for risk. This strategy ensures users remain supported while prioritizing clinical safety. In our system, when automated checks flag user input that contains a potential risk, clinicians are alerted with messages such as:

This system results in optimal conversation flows and escalations in interactions like the following:
——————————————————————————————————————————
Client: got into a bad fight with my roommate and it just completely put me over the edge of being done with everyone and everything. it's just not worth it to put up with this anymore.
AI: It sounds like things have been overwhelming for you lately. When you say it’s not worth it to put up with this anymore, are you having thoughts of harming yourself?
Client: No, not like that, just so over all the drama and stress it's just so much.
AI: Thanks for clarifying. That sounds like a lot to carry, Sarah. I wonder—what’s been the hardest part of all this for you?
——————————————————————————————————————————
This kind of clarification allows Sage to gather more context, support the user, and make a safer, more informed decision. If needed, Sage can alert the clinician through the Jimini Therapist Portal. By ensuring risk has been clarified or confirmed within the interaction with a client, clinicians overseeing these interactions can be confident that alerts warrant their valuable time and attention.
Again contrasting with use cases in comparable high-risk domains such as autonomous vehicles, an additional complexity of applications in patient-facing AI is that continuation may be the safest route in certain contexts. Whereas in vehicles the safest response to uncertainty is often to pause or stop entirely, in mental health the inverse is frequently true. When a patient is expressing something highly complex and potentially concerning, that may be precisely the moment to stay engaged and learn more. Refusing service too quickly in these moments risks missing critical context or worse, leaving the person feeling unheard or abandoned.
Of course, the appropriate response is not always the same even once a potential risk is identified. Depending on the setting, the appropriate escalation path can vary dramatically—from taking no immediate action, flagging a therapist for follow-up, involving a care manager or support team, and in rare cases initiating emergency services. A one-size-fits-all approach to risk fails to account for the nuances of clinical presentation, therapeutic rapport, and individual client history. This is what makes clinical oversight and alignment essential. Escalation decisions must be made in light of the full therapeutic context, guided by human judgment and the norms of the care environment. Systems that are tightly integrated with clinicians can make more accurate, appropriate decisions about when to intervene and how, ultimately improving both safety and trust.
Conclusion: Patient Facing AI at Scale Enabled by Safety
Patient-facing AI will have a world-changing impact in healthcare, and certainly in mental health. The standards for safety here must reflect the complexity of clinical work, the consequences of getting it wrong, as well as the sheer complexity of large language models.
The framework described here is not speculative and is already in use. Jimini suggests that all LLM-native companies designing patient-facing AI follow similar protocols.
This work reflects a view we hold strongly: that safety is not a tradeoff with scale, but it is what makes scaling possible. To achieve safety and innovation at scale, the framework above helps ensure that safety is moving in lockstep with innovation.
There is more to build. But a safer, more responsible path is not out of reach. It’s already underway.
References
- National Alliance on Mental Illness. Mental health by the numbers. [Internet] April 2023. Available from: https://www.nami.org/about-mental-illness/mental-health-by-the-numbers/
- Diena, Y. Key therapist statistics & demographics [Internet]. Ambitions ABA; 2025 Feb 25 Available from: https://www.ambitionsaba.com/resources/therapist-statistics
- Leichsenring F, Steinert C, Rabung S, Ioannidis JP. The efficacy of psychotherapies and pharmacotherapies for mental disorders in adults: an umbrella review and meta-analytic evaluation of recent meta-analyses. World Psychiatry. 2022; doi:10.1002/wps.2094
- Li L, Peng W, Rheu MM. Factors predicting intentions of adoption and continued use of artificial intelligence chatbots for mental health: examining the role of UTAUT model, stigma, privacy concerns, and artificial intelligence hesitancy. Telemed J E Health. 2024;30(3):722–30. https://doi.org/10.1089/tmj.2023.0313
- De Freitas J, Uğuralp AK, Oğuz‐Uğuralp Z, Puntoni S. Chatbots and mental health: Insights into the safety of generative AI. J Consum Psychol. 2024;34(3):481–91. https://doi.org/10.1002/jcpy.1393
- Scholich T, Barr M, Stirman SW, Raj S. A comparison of responses from human therapists and large language model–based chatbots to assess therapeutic communication: Mixed methods study. JMIR Ment Health. 2025;12(1):e69709. https://mental.jmir.org/2025/1/e69709/
- Zao-Sanders M. How people are really using gen AI in 2025 [Internet]. Harvard Business Review. 2025 Apr 9. Available from: https://hbr.org/2025/04/how-people-are-really-using-gen-ai-in-2025
- Casu M, Triscari S, Battiato S, Guarnera L, Caponnetto P. AI chatbots for mental health: a scoping review of effectiveness, feasibility, and applications. Appl Sci. 2024;14(13):5889. https://doi.org/10.3390/app14135889
- Browning, K. Character.AI faces lawsuit over teen’s suicide. The New York Times. 2024 Oct 23. Available from: https://www.nytimes.com/2024/10/23/technology/characterai-lawsuit-teen-suicide.html
- Castillo E, Khan S, King D, Moon K, Rafla-Yuan E, Yellowlees P. Position statement on the role of augmented intelligence in clinical practice and research [Internet]. Washington (DC): American Psychiatric Association; 2024 Mar. Available from: https://www.psychiatry.org/getattachment/a05f1fa4-2016-422c-bc53-5960c47890bb/Position-Statement-Role-of-AI.pdf
- American Psychological Association. APA Services’ policy principles to ensure the effective and fair regulation of artificial intelligence [Internet]. Washington (DC): APA Services. Available from: https://www.apaservices.org/advocacy/artificial-intelligence-factsheet.pdf
- U.S. Food and Drug Administration. Total product lifecycle considerations for generative AI-enabled devices: executive summary for the Digital Health Advisory Committee meeting [Internet]. Silver Spring (MD): FDA; 2024 Nov 20–21. Available from: https://www.fda.gov/media/182871/download
- American Psychological Association. Using generic AI chatbots for mental health support: a dangerous trend [Internet]. Washington (DC): APA; 2024 Apr. Available from: https://www.apaservices.org/practice/business/technology/artificial-intelligence-chatbots-therapists
- Bucky SF, Callan JE, Stricker G. Ethical and legal issues for mental health professionals: a comprehensive handbook of principles and standards. New York: Routledge; 2013.
- Boucher EM, Raiker JS. Engagement and retention in digital mental health interventions: A narrative review. BMC Digit Health. 2024 Aug 8;2(1):52. https://doi.org/10.1186/s44247-024-00105-9
- Werntz A, Amado S, Jasman M, et al. Providing human support for the use of digital mental health interventions: systematic meta-review. Clin Psychol Eur. 2023;5(4):e10025. https://doi.org/10.32872/cpe.10025
- Flückiger C, Del Re AC, Wampold BE, Horvath AO. The alliance in adult psychotherapy: A meta-analytic synthesis. Psychotherapy. 2018;55(4):316–40. https://doi.org/10.1037/pst0000172
- Flückiger C, Del Re AC, Wampold BE, Symonds D, Horvath AO. How central is the alliance in psychotherapy? A multilevel longitudinal meta-analysis. J Couns Psychol. 2012;59(1):10–17. https://doi.org/10.1037/a0025749
- Probst GH, Berger T, Flückiger C. The alliance-outcome relation in internet-based interventions for psychological disorders: A correlational meta-analysis. Verhaltenstherapie. 2022;32(Suppl. 1):135–46. https://doi.org/10.1159/000525966
- Lee H, Reece AG, Jamison KW, et al. Artificial intelligence for mental health: a call for caution, context, and care. Nat Ment Health. 2024;1:19. https://doi.org/10.1038/s44184-024-00056-z
- Amodei D. The urgency of interpretability [Internet]. 2025 Apr. Available from: https://www.darioamodei.com/post/the-urgency-of-interpretability
* With contributions from: Seth Feuerstein, Tim Althoff, Bill Hudenko, Mark Jacobstein, Sahil Sud, Colin Adamo, Johannes Eichstaedt, Chiara Waingarten, Luis Voloch, Pushmeet Kohli

